티스토리 뷰
1. 관계형 데이터 모델
1.1 데이터 모델의 구성 요소
- 데이터 모델은 데이터 구조와 연산, 제약 조건와 같이 3가지 요소로 구성된다.

데이터 구조
- 데이터를 어떤 형태로 저장하는지를 표현
연산
- 데이터를 어떤 방식으로 처리하는지를 표현
제약 조건
- 데이터 구조를 지정할 때의 구조적 제약 사항과 연산을 적용할 때의 행위적 제약 사항을 표현
1.2 관계형 데이터 모델의 구성 요소
- 관계형 데이터 모델은 테이블 형태의 릴레이션을 통해 데이터를 저장하고 데이터 간의 관련성도 표현
- 데이터 구조는 릴레이션, 연산은 관계 대수, 제약 사항은 무결성 제약 조건으로 명세
2. 관계형 데이터 구조
2.1 관계형 데이터 구조의 개념
- 릴레이션
- 1970년대 IBM 연구소의 E. F. Codd가 제안한 데이터 모델에 기반
- 이론적으로는 릴레이션이라는 수학적 집합 개념에 기초
- 2차원 테이블 형태의 단순한 구조에 데이터를 저장하는 방식
- 실제 저장 방식은 다르지만 테이블 구조는 릴레이션 개념을 직관적으로 쉽게 이해하도록 함

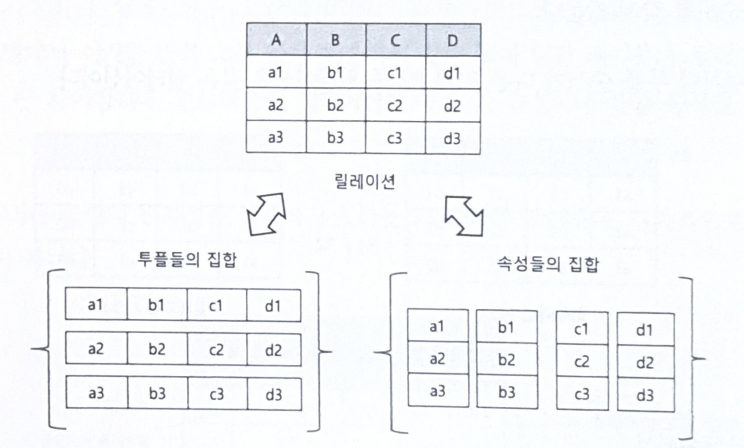
- 1) 속성(열, 필드)과 튜플(행, 레코드)
- 테이블의 열을 릴레이션에서는 속성이라 부름
- 릴레이션이 표현하는 대상의 주요 특성들을 서로 다른 이름으로 구별하여 표현
- 테이블의 열을 릴레이션에서는 튜플이라 부름
- 현실 세계이 개체를 튜플로 표현
2) 도메인
- 각 속성은 데이터를 표현하는 가장 작은 논리적 단위
- 의미적으로 더 이상 분해할 수 없는 원자 값만 사용 가능
- 각 속성이 취할 수 있는 모든 값들의 집합을 정의한 것을 도메인이라 함
- 데이터의 타입과 크기, 범위를 정의
- 속성 이름과는 별개로 각 도메인을 고유한 이름으로 정의
- 도메인이 같아야 속성끼리 값 비교가 가능

3) 카디널리티와 차수
- 카디널리티
- 전체 튜플의 개수
- 차수
- 전체 속성의 개수
*릴레이션의 최소 카디널리티는 0, 최소 차수는 1
2.2 릴레이션의 구성 요소
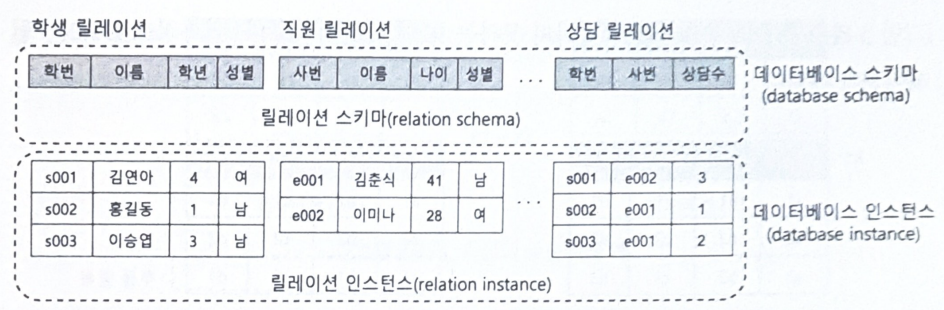
릴레이션 스키마와 릴레이션 인스턴스 2가지 요소로 구성
1) 릴레이션 스키마
- 릴레이션의 이름과 릴레이션 안에 포함된 모든 속성의 이름들로 정의
- 릴레이션 내포(intension)라고도 부름
- 시간이 지나도 좀처럼 변경되지 않는 정적인 특성
2) 릴레이션 인스턴스
- 릴레이션 스키마에 따라 각 속성에 대응하는 임의의 속성 값을 갖는 튜플들
- 특정 시텀에 릴레이션에 존재하는 튜플들의 집합
- 릴레이션 외연(extension)이라고도 부름
- 시간에 따라 변하는 동적인 특성

데이터베이스 스키마와 데이터베이스 인스턴스
1) 데이터베이스 스키마
- 릴레이션 스키마들의 모임
2) 데이터베이스 인스턴스
- 특정 시점에서의 릴레이션 인스턴스들의 모임
2.3 릴레이션의 특성
- 단순한 테이블로 보이지만 수학적 관점에서는 하나의 집합이기 때문에 다음과 같은 4가지 특성을 가진다.
1) 튜플의 유일성
- 릴레이션 안에는 똑같은 튜플이 존재할 수 없다. 집합은 식별할 수 없는 똑같은 원소를 중복해서 포함할 수 없기 때문
2) 튜플의 무순서성
- 집합은 포함된 원소들 사이에 순서가 없다.
3) 속성의 무순서성
- 위와 같은 이유
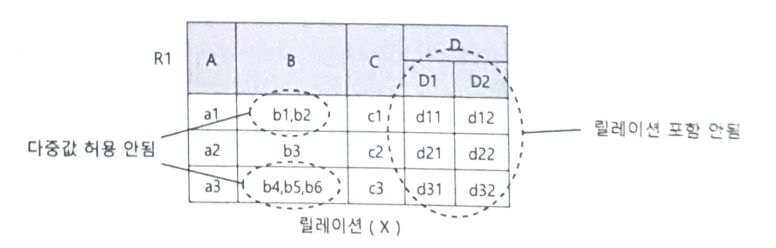
4) 속성의 원자성
- 모든 속성 값은 의미적으로 더 이상 분해할 수 없는 하나의 원자 값만을 가짐
- 다중 값 속성이나 복합 속성을 허용하지 않음
속성의 원자성을 만족하지 못하는 릴레이션의 예
3. 제약 조건
- 데이터베이스 내 데이터는 결함이 없어야 함. 데이터의 신뢰성을 유지하기 위해 사용
- 데이터를 릴레이션에 저장할 때 만족해야할 구조적 제약 사항과 관계 대수 연산을 적용할 때 만족해야할 행위적 제약 사항을 포함
3.1 릴레이션의 키
- 릴레이션은 항상 튜플의 유일성 규칙을 만족하므로 중복 튜플을 허용하지 않음
- 각 튜플을 유일하게 식별할 수 있는 하나 이상의 속성 집합을 릴레이션의 키라 함
- 모든 릴레이션은 키를 가짐
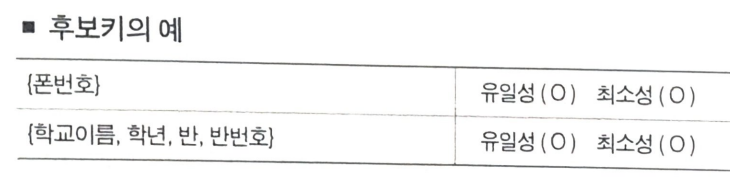
후보키
- 튜플을 유일하게 식별할 수 있는 속성들의 최소 집합
슈퍼키
- 튜플을 유일하게 식별할 수 있는 속성 집합
- 유일성 조건만 만족하면 됨

기본키
- 튜플을 대표하도록 선정된 후보키
- 여러 후보키 중에서 하나를 기본키로 선택

기본키 선정 기준
- 값이 자주 변경되지 않는 정적인 속성으로 구성된 후보키
- 널 값을 가질 수 없는 속성으로 구성된 후보키
- 속성 개수가 작은 후보키
- 속성 값의 물리적 크기가 작은(숫자 크기가 작거나 문자열 길이가 짧은) 후보키
-> 성능 상의 이점을 위해
* 기본키는 릴레이션의 기본 접근 수단으로, 매우 중요함
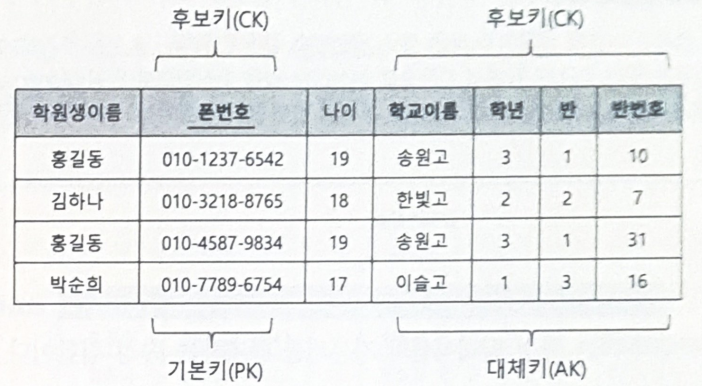
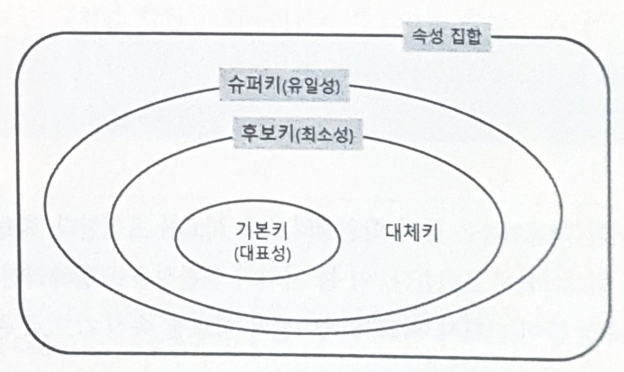
대체키(Alternate Key)
- 기본키로 선정되지 못한 후보키
대리키(Surrogate Key)
- 후보키 중에서 적절한 기본키 선정이 어려울 경우, 일련번호 같은 인위적인 속성을 추가하여 기본키로 지정
- DBMS 등에서 자동으로 생성하는 값을 저장하므로 인공키라고도 부름
외래키
- 특정 릴레이션의 기본키를 참조하는 속성 집합
- 기본키와 외래키는 릴레이션 간의 연광성을 표현
외래키에 속하는 모든 속성 값은 반드시 특정 릴레이션의 기본키 값 중 하나와 일치해야 함
참조하는 릴레이션은 자식 릴레이션, 참조되는 릴레이션을 부모 릴레이션이라 함
스스로를 참조하는 경우도 존재
널 값을 가질 수 있음.

3.2 무결성 제약 조건
- 모든 데이터들을 의미적으로 흠 없이 항상 정확하고 완전한 상태로 유지하기 위해 적용해야할 제약 사항
- DBMS를 통해 간단한 무결성 제약 조건 설정. DBMS는 이를 해석하여 데이터를 입력, 수정, 삭제할 때마다 제약 조건을 자동적으로 검사하여 적용
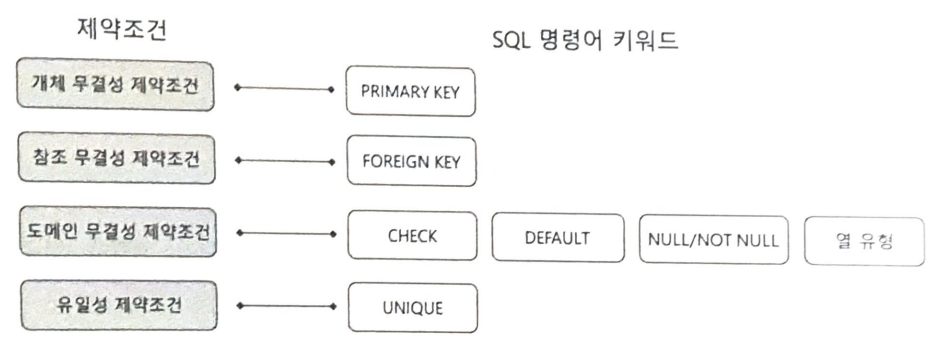
개체 무결성 제약 조건
- 기본키로 지정한 모든 속성은 널 값을 가질 수 없고 릴레이션 안에서 중복되지 않는 유일한 값을 가져야 한다는 제약 사항
- 기본키 제약 조건이라고도 함
- DBMS에게 기본키를 선언함으로써 즉시 적용
참조 무결성 제약 조건
- 외래키로 지정한 속성은 참조하는 릴레이션의 기본키 속성 값과 일치하는 값이나 널 값만을 가져야한 다는 제약 사항
- 외래키 제약 조건이라고도 함
- DBMS에게 외래키를 선언함으로써 즉시 적용 가능
- 의미적으로 연관된 두 릴레이션 튜플 사이의 일관성 유지를 위해 사용
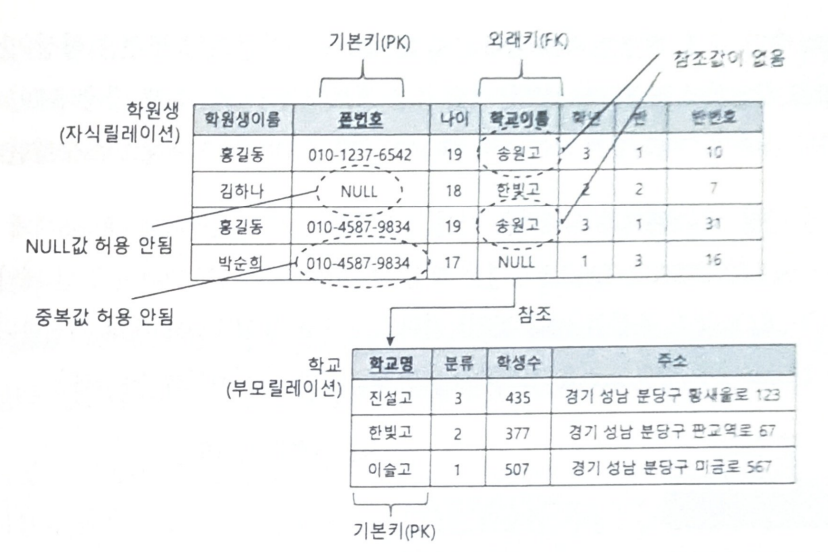
기본키는 개체 식별자 역할을, 외래키는 개체 참조자 역할을 수행함
도메인 무결성 제약 조건
- 튜플의 모든 속성 값이 각 속성의 도메인에 속한 값만을 취해야 한다는 제약 사항
유일성 제약 조건
- 모든 키 속성 값이 서로 중복되지 않고 유일해야 한다는 제약 사항
- 키 제약 조건이라고도 함
4. 관계 연산
- 관계형 데이터 모델에서 릴레이션을 조작하기 위한 연산
- 대표적인 2가지 표현 방법: 관계 대수(relational algebra), 관계 해석(relational calculus)
관계 대수
- 사용자가 필요로 하는 데이터를 획득하는 절차 ,즉 연산들의 적용 순서를 명세
- 관계 연산의 기본 토대를 제공하고, 몇몇 개념은 SQL에 반영되어 있음
- DBMS가 내부적으로 질의를 구현하고 최적화하기 위한 기반으로 사용
- 대부분의 핵심 연산과 기능들이 관계 대수 연산에 기반
관계 해석
- 사용자가 필요한 데이터가 무엇인지, 연산들의 최종 결과만을 명세
관계 대수와 관계 해석의 차이점
- 관계 대수가 어떻게에 중점을 둔다면, 관계 해석은 무엇을에 중점
- 형식 언어로서 둘 다 DBMS가 직접 지원하지는 않으므로, 실제 사용할 수 있는 데이터 언어는 아님
- 대신 SQL 언어의 작성 방법이나 내부 처리 방식의 이론적 기반을 제공
'데이터베이스' 카테고리의 다른 글
| [데이터베이스] #7. 내장함수, 저장 프로시저, 트리거 (0) | 2021.12.26 |
|---|---|
| [데이터베이스] #5. 뷰 (0) | 2021.12.26 |
| [데이터베이스] #4. 관계 대수 (0) | 2021.12.21 |
| [데이터베이스] #2. 데이터베이스 시스템 (0) | 2021.12.20 |
| [데이터베이스] #1 데이터베이스 개념 (0) | 2021.12.20 |