티스토리 뷰
트랜잭션
- 한 묶음으로 처리되어야 하는 SQL 문들의 집합
- 트랜잭션에 속한 SQL 문들은 모두 정상처리 되어야 트랜잭션이 완료될 수 있음
- 트랜잭션의 실행 결과를 데이터베이스에 최종적으로 반영하는 것을 커밋이라 함
- 실행 결과를 반영하지 않고, 취소하여 원래 상태로 되돌리는 것을 롤백이라 함
- 커밋되기 전까지는 데이터베이스에 완전하게 반영되었다고 할 수 없는 임시 실행 결과일 뿐
필요성
- 여러 사용자의 동시 접근성을 제어하고 장애 발생 시 안정적으로 데이터를 복구하기 위해
트랜잭션의 4가지 특성(ACID)
1) 원자성(Atomicity)
- 트랜잭션 안의 SQL 명령문을 모두 성공적으로 실행하여 완료하거나 아니면 모두 철회하여 무효화해야함을 의미
2) 일관성(Consistency)
- 데이터베이스가 트랜잭션 실행 전의 일관된 상태에서 실행 후에도 또 다른 일관된 상태로 전환되어야함을 의미
- 동시 실행되는 트랜잭션 사이의 상호 간섭을 락과 같은 수단을 통해 제어함으로써 데이터의 일관성을 유지
3) 고립성(Isolation)
- 커밋될 때까지 트랜잭션이 수행한 임시 실행 결과가 다른 트랜잭션에게 공개되지 않아야함을 의미
- 커밋 전까지는 락을 통해 다른 트랜잭션의 접근 방지
4) 지속성(Durability)
- 일단 트랜잭션이 커밋되면 그 실행 결과는 장애가 발생하더라도 최종적으로 저장 장치에 반영되는 것을 보장함을 의미
트랜잭션 지원하기 위한 DBMS 모듈
1) 동시성 제어 모듈
- 동시에 실행되는 트랜잭션 간의 간섭 제어
- 대표적 기법은 락
2) 회복 모듈
- 완전한 트랜잭션 결과의 복구 보장
- 대표적 기법은 로깅

트랜잭션의 종류
- 트랜잭션은 설정 모드에 따라 3가지 트랜잭션으로 구분 가능

명시적 트랜잭션
- 트랜잭션의 시작과 끝을 사용자가 직접 명시적으로 저장하는 트랜잭션
- 사용자 트랜잭션 또는 수동 트랜잭션
자동완료 트랜잭션
- 특별한 설정이 없을 경우 적용되는 기본 모드의 트랜잭션
- SQL문의 실행 결과에 따라 자동으로 커밋 또는 롤백하는 트랜잭션
- 시스템 트랜잭션
- 모든 SQL 문장 하나하나가 실행되고, 문제가 없으면 자동으로 커밋되기 때문에 롤백 명령문을 임의로 넣어도 적용되지 않음
수동완료 트랜잭션
- 트랜잭션의 끝만 사용자가 직접 명시적으로 지정하는 트랜잭션
- 암시적 트랜잭션
- 트랜잭션이 커밋된 상태가 아니므로 언제든지 취소될 수 있음 - 실행 결과를 확정하려면 반드시 COMMIT 명령문을 실행해야 함
트랜잭션과 로그
- SQL 처리 작업은 램에서 이루어지므로, 처리 중 장애가 발생할 경우 처리 결과가 소실되는 문제가 발생할 수 있음
- 로그 회복은 장애 발생에 대한 안전한 복구를 지원하기 위한 대표적 기법
트랜잭션 처리 과정
- 먼저, 데이터 변경 요청이 데이터베이스 서버로 들어오면, DBMS의 쿼리 처리기를 통해 SQL문들이 접수되어 해석된다. 다음으로 검색 또는 변경 대상이 되는 데이터 페이지 블록들이 디스크 안의 저장 데이터베이스 파일로부터 램의 데이터베이스 버퍼 캐시 영역으로 로드된다. 찾는 페이지가 이미 데이터베이스 버퍼 캐시에 있다면 다시 로드되지 않는다. 해석된 SQL 문들은 데이터베이스 버퍼 캐시 안의 해당 페이지를 대상으로 검색하거나 데이터 페이지 내용을 변경한다. 버퍼 캐시 안의 데이터 페이지가 성공적으로 변경되면 디스크 안의 저장 데이터베이스 파일에 쓰여져야 하는데 보통 즉시 디스크에 반영되지 않는다. 이러한 지연 쓰기 전략은 버퍼 캐시 안의 페이지들을 다시 요청하는 경우를 위해 디스크 입출력 횟수를 줄여 성능을 향상시키기 위해서다.

로그 먼저 쓰기 규약(write-ahead log protocol)
- 가장 최근 데이터는 대부분 버퍼 캐시 안에 남게된다. 휘발성 저장 장치인 버퍼 캐시 내용이 디스크 기록 이전에 장애가 발생하여 삭제될 수 있다는 문제가 있다
- 트랜잭션 실행 기록인 로그는 매번 트랜잭션 처리 직전에 먼저 디스크 안의 로그 데이터베이스 파일에 안전하게 기록한다
로그 데이터베이스
- 트랜잭션의 모든 데이터 변경 사항을 저장 데이터베이스에 반영하기 전에 미리 기록하는 데이터베이스
- 로그는 트랜잭션 처리 정보; 하드웨어, 소프트웨어 오류, 장치 손실, 자연 재해 등의 장애로 인해 주기억 장치와 디스크 안의 데이터가 손실되는 것에 대비하여 추후 복구를 위해 저장
백업 데이터베이스
- 데이터베이스의 물리적 손상에 대비하여 별도로 저장한 복제 데이터베이스
- 매번 전체 데이터베이스의 복사본을 저장하는 전체 백업과 이전 전체 데이터베이스의 복사본과 차이가 있는 변경 데이터 부분만 추가로 백업하는 차등 백업, 전체 데이터베이스 복사본과 이후 로그 데이터베이스 복사본을 저장하는 증분 백업 등이 있음
- DBMS는 복원와 회복을 지원하기 위해 정기적 백업과 로깅, 체크포인트를 수행
트랜잭션 로그
- 로그를 통한 회복의 기본 단위 역시 트랜잭션
- 장애 발생 시 트랜잭션 단위로 회복을 진행하기 위해 트랜잭션 로그를 로그 데이터베이스에 저장
- 로그 일련번호, 트랜잭션 식별자, START, COMMIT, ROLLBACK, 명령문 유형과 변경 내용 등이 기록
체크포인트
- 특정 시점까지의 데이터 버퍼 안의 모든 변경 내용을 데이터베이스 파일에 물리적으로 저장하는 시점
- 체크포인트 역시 로그에 기록
- 회복 대상을 마지막 체크포인트 시점 이후의 내용으로만 제한
- 체크포인트가 트랜잭션 로그에 기록되는 순간 모든 데이터 버퍼 안의 데이터들이 데이터베이스 파일에 쓰여짐
로그를 이용한 회복 기법
- 회복의 기본 개념은 장애 발생 시점에 이미 커밋도니 트랜잭션의 변경 내용은 로그를 이용하여 반드시 데이터베이스에 반영한다는 것
1. 회복은 장애 발생 시점에 중단된 트랜잭션의 작업 내용을 롤백시키기 위해 로그 기록의 역순으로 이전 상태로 되돌리는 undo 작업 진행
2. 마지막 체크포인트 이후의 커밋되지 않은 트랜잭션의 로그 내용들은 모두 롤백
3. 반대로, 장애 발생 시점까지 정상적으로 종료된 트랜잭션의 실행 결과를 보장하기 위해서는 로그 기록의 순서대로 다시 실행(redo)작업 진행
4. 마지막 체크포인트 이후의 커밋된 트랜잭션의 로그 내용들은 모두 롤포워드(roll-forward); 로그 순서대로 재실행
트랜잭션 로그 기반 회복의 예
[T1, START]
[T1, UPDATE, 학생(김연아).중간성적, 88, 99] 1
[T2, START]
[T2, UPDATE, 학생(박찬호).기말성적, 89, 93] 2
[CHECKPOINT]
[T2, UPDATE, 학생(이승엽).기말성적, 77, 66] 3
[T1, UPDATE, 학생(이영애).중간성적, 91, 97] 4
[T1, COMMIT]
~~~~~~~~장애 발생 5
트랜잭션 T1은 장애 발생 이전에 커밋되어 정상 완료되었다
1. 체크포인트 시점 이전의 T1의 UPDATE문의 실행 결과는 데이터베이스 파일에 이미 기록되었으므로 처리할 내용이 없다.
4. 반면 체크포인트 시험 이후의 T1의 UPDATE문의 실행 결과는 지연 갱신으로 버퍼 캐시에 남아있다. 장애 발생 사라졌으므로 로그를 참조하여 반드시 재실행해야 한다.
-> 커밋 후 장애가 발생했으므로 커밋된 트랜잭션의 데이터베이스 반영을 보장해야 한다. 가장 최근의 체크포인트 시점부터 이후의 실행 로그 기록을 참조하여 시간 순서대로 재실행한다.
트랜잭션 T2은 장애 발생으로 커밋되지 않은 채 비정상 완료되었다
2. 체크포인트 시점에 데이터베이스 파일에 이미 반영된 T2의 UPDATE문의 처리 결과는 반드시 취소해야 한다.
3. 체크포인트 시점 이후의 T2의 UPDATE문의 실행 결과는 지연 갱신으로 버퍼 캐시에 남아있다 장애 발생 시 사라졌으므로 처리할 내용이 없다.
-> 커밋 전에 장애가 발생했으므로 트랜잭션의 실행을 취소해야 한다. 시간의 역순으로 로그 기록을 참조하여 실행 내역을 취소한다. 체크포인트 이후의 실행 결과는 데이터베이스 파일에 반영된 결과가 있다면 선택적으로 취소하지만 체크포인트 이전의 실행 결과는 반드시 취소해야 한다.
트랜잭션과 락
- 데이터베이스에는 여러 사용자가 동시에 같은 데이터에 접근할 수 있다. 적절한 절차 없이 동시 접근을 허용할 경우, 여러 심각한 문제들이 발생할 수 있다.
락의 개념
- 바람직한 동시성이란 2개 이상의 트랜잭션을 동시에 실행하는 비직렬 스케줄의 결과가 트랜잭션을 뒤섞지 않고 순차적으로 실행하는 직렬 스케줄의 결과와 같도록 보장하는 것.
- 이를 보장하는 트랜잭션 스케줄을 '직렬 가능'이라 함
- 직렬 가능성을 보장하는 방법 중 하나가 '락'을 이용하는 것
- 락을 사용하는 동시성 제어 기법에서는 트랜잭션 내에서 데이터에 SQL 명령문을 실행하기 전에 반드시 해당 데이터에 락을 설정해야함
- 또, 설정된 락은 SQL 명령문 실행 직후가 아닌 트랜잭션 커밋 혹은 롤백이 실행됨과 동시에 해제해야 함
락의 종류
1. 공유 락
- 데이터를 검색하는 SELECT문을 실행하기 위한 읽기 전용 락
- 공유 락이 설정된 데이터에 대해서는 추가적으로 공유 락을 설정할 수 있음
2. 독점 락
- INSERT, UPDATE, DELETE문과 같은 데이터 변경을 위한 배타적 락
- 특정 데이터에 대해서 오직 하나의 트랜잭션만 독점 락을 설정할 수 있음
- 이미 독점 락이 설정되어 있을 경우, 공유 락도 독점 락도 모두 추가적으로 설정할 수 없음
락 단위
- 데이터베이스 안의 모든 데이터에 접근할 때는 먼저 락 테이블 안에 해당 데이터에 대한 락 정보를 기록
- 락 잠금 대상의 크기를 락 단위라함
- 테이블 행 단위나 테이블, 데이터베이스 단위로 락을 설정할 수 있음
- 가장 작은 락의 단위는 테이블의 행
- 다른 행에 락을 설정할 수 있기 때문에 동시성은 좋아지지만 많은 행을 여러 차례 반복해 락을 설정하는 경우, 페이지나 테이블처럼 큰 범위로 락을 한 번에 설정하고 빨리 락을 해제하는 것이 더 성능을 향상시킬 수도 있음
- 락 단위가 커지면 관리하기는 쉬워지지만 락의 충돌이 자주 발생
락 양립성
- 독점 락과 공유 락 2가지 유형의 락 사이에는 서로 추가 잠금 허용 여부를 결정하는 락 양립성(lock compatability) 규칙이 있음

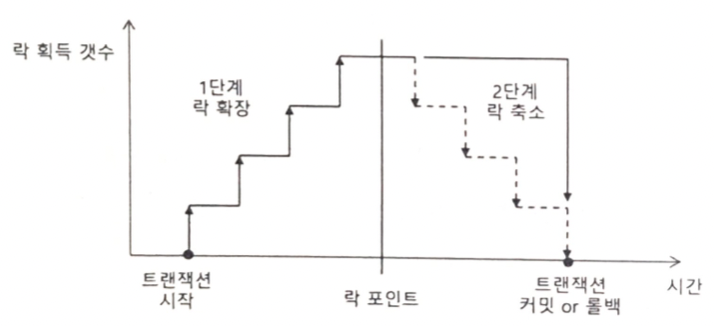
2단계 락킹 규약(2-phase locking protocol)과 락 해제
- 단지 락을 설정했다고 해서 동시성 제어가 완벽하게 이루어지지는 않음
- 락을 너무 일찍 해제할 경우, 트랜잭션의 고립성이 손상되어 데이터 일관성이 유지되지 않음
- 2단계 락킹 규약은 각 트랜잭션 별로 락을 설정하는 과정과 락을 해제하는 과정 2단계로 진행함으로써 필요한 순간까지 획득한 락을 유지하도록 하는 규칙
1단계: 락 확장 단계(growing phase)
- 접근하고자 하는 데이터에 대한 모든 락을 획득할 때까지 새로운 락을 지속적으로 요청하여 잠금 설정
- 보유하고 있는 락을 해제할 수는 없고 락을 추가로 획득할 수만 있음
2단계: 락 축소 단계(shrinking phase)
- 필요로 하는 모든 락을 획득하는 시점인 락 포인트가 되면 보유하고 있던 락을 점차적으로 해제
- 계단식으로 하나씩 해제할 수도 있지만 대부분 완료(커밋 혹은 롤백) 시점에 한꺼번에 모든 락을 해제
- 일단 하나라도 락을 해제하기 시작하면 다시 새로운 락을 요청할 수 없음
교착 상태
- 둘 이상의 트랜잭션의 락이 서로 얽혀서 풀리지 않는 상태
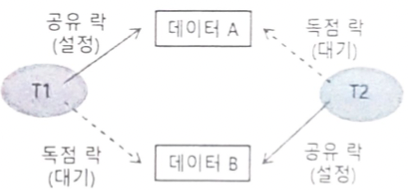
- 일반적인 교차 상태 회피 방법처럼 데이터를 모든 트랜잭션이 특정 순서에 따라 차례대로 락을 획득하도록 하는 것이 바람직
- 만약 교착 상태가 발생한 경우, 트랜잭션 중 처리 시간이 가장 적게 소요된 트랜잭션을 교착 상태의 희생자로 지정하여 강제로 롤백
트랜잭션의 고립 수준
- 락을 설정하는 목적은 적절한 수준에서 트랜잭션 동시 실행이 이루어지도록 하기 위해서
- 락 관리를 느슨하게 할 경우, 원치 않는 결과
- 락 관리를 엄격하게 할 경우, 동시 접근성이 감소해 성능 저하
- 필요로 하는 트랜잭션의 실행 수준에 따른 다양한 고립 수준을 정의하고 상황에 맞는 적절한 수준의 잠금 전략을 수행해야 함
- 고립 수준(isolation level)은 트랜잭션이 다른 트랜잭션과 고립되는 정도를 의미
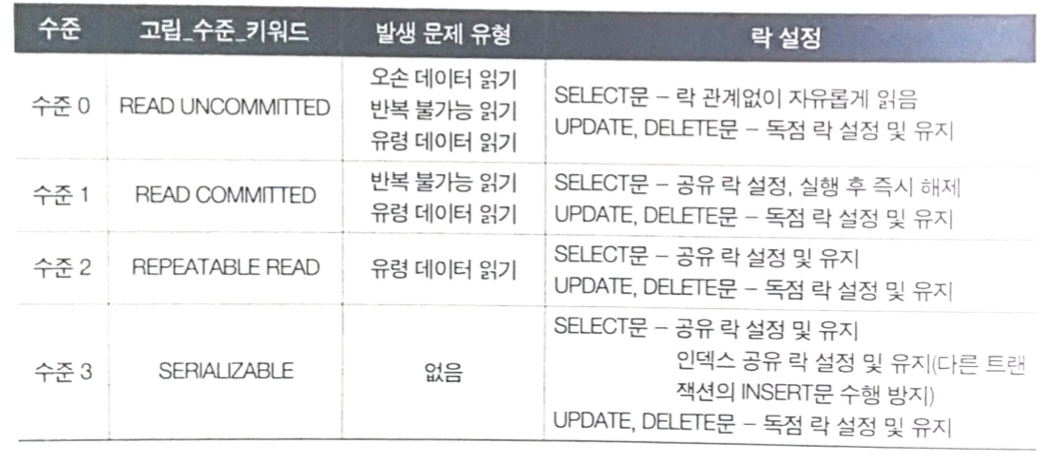
고립 수준에 따라 발생할 수 있는 문제 유형
1. 오손 데이터 읽기(dirty data read) 문제
- 커밋되지 않은 트랜잭션의 수정된 중간 결과를 읽어오는 것이 허용된다면 발생할 수 있는 문제
2. 반복 불가능 읽기(non-repeatable read) 문제
- 트랜잭션이 읽어서 처리 중인 데이터를 다른 트랜잭션이 자유롭게 변경하는 것이 허용된다면 발생할 수 있는 문제
3. 유령 데이터 읽기(phantom data read) 문제
- 트랜잭션이 같은 값을 반복해서 읽을 때 이전에 없던 다른 트랜잭션이 중간에 추가한 데이터, 즉 유령 데이터가 나타날 수 있음
고립 수준이 높아질 수록 동시 수행성을 제한하기 때문에 트랜잭션 처리의 성능 저하를 가져오는 반면에 데이터 정확성은 높아진다
'데이터베이스' 카테고리의 다른 글
| [데이터베이스] #10. E-R 모델 (0) | 2021.12.26 |
|---|---|
| [데이터베이스] #9. 정규화 (0) | 2021.12.26 |
| [데이터베이스] #7. 내장함수, 저장 프로시저, 트리거 (0) | 2021.12.26 |
| [데이터베이스] #5. 뷰 (0) | 2021.12.26 |
| [데이터베이스] #4. 관계 대수 (0) | 2021.12.21 |